引言
ObjectOutputStream 是序列化的关键类,用于将对象转化为二进制流。可以通过 ObjectInputStream 将二进制流还原成对象。序列化是需要注意以下几点:
- 要序列化的类须实现 Serializable 接口
- 反序列化后的类的 serialVersionUID 和对象二进制流的 serialVersionUID 必须相同
- 序列化会把类的引用中所有的成员变量保存下来,所以引用的类型也要实现 SerialVersionUID
- 可以使用 transient 关键字来指定不采用默认序列化或者不需要序列化的成员变量
- 每个类可以实现 readObject 和 writeObject 来实现自定义的序列化策略,即使是 transient 修饰的变量也可以手动调用 ObjectOutputStream#writeInt() 等方法来序列化
源码解析
构造函数
public ObjectOutputStream(OutputStream out) throws IOException {
verifySubclass(); // 如果有子类继承该类,检查子类的继承权限
bout = new BlockDataOutputStream(out); // 实际由它向 out 写入序列化数据
handles = new HandleTable(10, (float) 3.00); // 类似 HashMap,用于存储和查找 Obj
subs = new ReplaceTable(10, (float) 3.00);
enableOverride = false; // 恒为 false,除非子类调用 protected 构造方法
writeStreamHeader();
bout.setBlockDataMode(true); // 打开缓存模式,那么写入数据是往缓存写的
if (extendedDebugInfo) {
debugInfoStack = new DebugTraceInfoStack();
} else {
debugInfoStack = null;
}
}
可以看出它主要就是:
- 检查子类(如果有的话)是否有继承权限
- 创建 BlockDataOutputStream,序列化的数据实际是保存在该类中,并由它写到传进来的输出流
- 创建 HandleTable 等来保存对象
我们来看下1:
/**
* 确认 ObjectOutputStream(可能是它的子类)实例没有违反安全限制:
* 即子类不能重写非 final 的安全敏感的方法,否则"enableSubclassImplementation"
* 权限就会不通过
*/
private void verifySubclass() {
Class<?> cl = getClass();
// 如果没有子类,直接返回
if (cl == ObjectOutputStream.class) {
return;
}
// 获取安全管理器
SecurityManager sm = System.getSecurityManager();
if (sm == null) {
return;
}
// 清空缓存中失去引用的 Class 对象
processQueue(Caches.subclassAuditsQueue, Caches.subclassAudits);
// 判断子类是否在缓存,不在的话放进去
WeakClassKey key = new WeakClassKey(cl, Caches.subclassAuditsQueue);
Boolean result = Caches.subclassAudits.get(key);
if (result == null) {
result = Boolean.valueOf(auditSubclass(cl));
Caches.subclassAudits.putIfAbsent(key, result);
}
if (result.booleanValue()) {
return;
}
// 开始检查权限,没有权限就抛出异常
sm.checkPermission(SUBCLASS_IMPLEMENTATION_PERMISSION);
}
可以看出它主要是:
- 判断如果不是子类则无需检查权限直接返回,流程结束。
- 是子类的话,先清空缓存中失去引用的 Class 对象,然后根据子类的 class 创建一个 key,通过该 key 去缓存中查找,没找到就将 class 放到缓存中
- 检查权限,没有的话就抛异常
我们来看下 2,它先去清缓存中事去引用的 Class 对象,然后创建一个 key。我们先看下缓存代表什么:
private static class Caches {
/** 缓存了子类的安全检查结果 */
static final ConcurrentMap<WeakClassKey,Boolean> subclassAudits =
new ConcurrentHashMap<>();
/** 已审查过的子类的弱引用队列 */
static final ReferenceQueue<Class<?>> subclassAuditsQueue =
new ReferenceQueue<>();
}
可以看出,这个缓存是用于存储子类的安全检查结果,以及审查通过的子类的弱引用队列。再来看看它是如何清除事去引用的 Class 对象的:
/**
* Removes from the specified map any keys that have been enqueued
* on the specified reference queue.
*/
static void processQueue(ReferenceQueue<Class<?>> queue,
ConcurrentMap<? extends
WeakReference<Class<?>>, ?> map)
{
Reference<? extends Class<?>> ref;
while((ref = queue.poll()) != null) {
map.remove(ref);
}
}
它是 ObjectStreamClass 类的方法,即清除 subclassAudits 中所有的 subclassAuditsQueue 包含的数据。再来看下 WeakClassKey:
static class WeakClassKey extends WeakReference<Class<?>> {
private final int hash;
WeakClassKey(Class<?> cl, ReferenceQueue<Class<?>> refQueue) {
// 第一个参数 cl 即为 referent,下面用它来判断两个 WeakClassKey 是否相等
super(cl, refQueue);
hash = System.identityHashCode(cl);
}
public int hashCode() {
return hash;
}
/**
* 相同的对象,或者不同的对象有相同的 referent 则返回 true
*/
public boolean equals(Object obj) {
if (obj == this) {
return true;
}
if (obj instanceof WeakClassKey) {
Object referent = get();
return (referent != null) &&
(referent == ((WeakClassKey) obj).get()); // 是否有相同的 referent
} else {
return false;
}
}
}
可以看出 WeakClassKey 里面存放 2 个对象,class 和 Queue。 equals 方法重写了,他会根据 class 是否相同来判断两个 WeakClassKey 是否相等。我们再来看下面这个方法:
/**
* The writeStreamHeader method is provided so subclasses can append or
* prepend their own header to the stream. It writes the magic number and
* version to the stream.
*
* @throws IOException if I/O errors occur while writing to the underlying
* stream
*/
protected void writeStreamHeader() throws IOException {
bout.writeShort(STREAM_MAGIC); // 写魔数
bout.writeShort(STREAM_VERSION); // 写版本号
}
它是用于将魔数和版本号写到流中作为 header,这样子类就能够往后追加,或者往前新增他们自己的 header 到流中。
写 String 流程
从上面可以看到,构造函数往流中首先写入魔数和版本号,那么整个流的结构是怎么样的呢?
首先来看下简单的写一个 String:
ByteArrayOutputStream byteArrayOutputStream = new ByteArrayOutputStream();
ObjectOutputStream objectOutputStream = new ObjectOutputStream(byteArrayOutputStream);
objectOutputStream.writeObject("Havana");
FileOutputStream fileOutputStream = new FileOutputStream(new File(Environment.getExternalStorageDirectory(), "stringSerial.txt"));
byte[] result = byteArrayOutputStream.toByteArray();
fileOutputStream.write(result, 0, result.length);
fileOutputStream.close();
String 序列化结构:
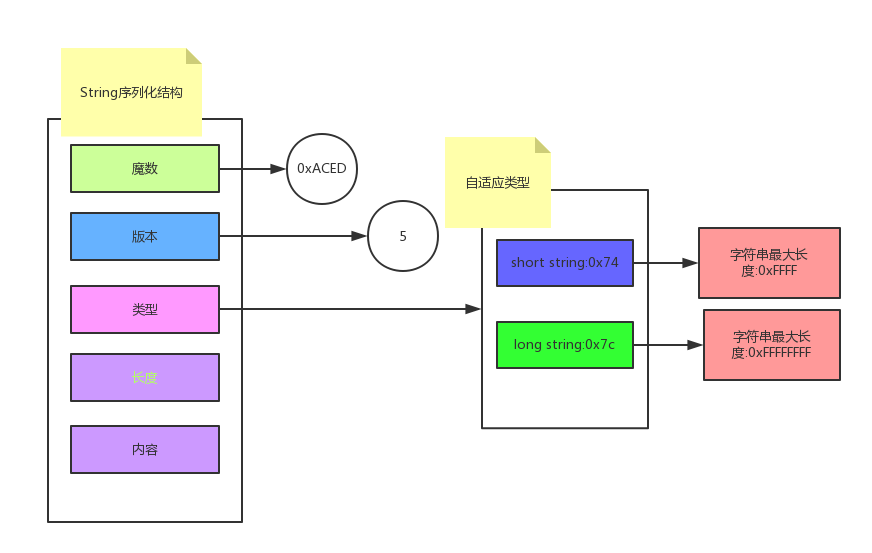
- 魔数:(short)0xaced
- 版本:5
- 类型:(Short String)0x74,(Long String) 0x7C
- 长度:0x0009
- 内容:Havana
我们来看下 ObjectOutputStream#writeString:
/**
* Writes given string to stream, using standard or long UTF format
* depending on string length.
*/
private void writeString(String str, boolean unshared) throws IOException {
handles.assign(unshared ? null : str);
long utflen = bout.getUTFLength(str);
if (utflen <= 0xFFFF) {
bout.writeByte(TC_STRING); // 完成第 3 步,写类型
bout.writeUTF(str, utflen);
} else {
bout.writeByte(TC_LONGSTRING);
bout.writeLongUTF(str, utflen);
}
}
- 将 str 放到 HandleTable 中,类似 HashMap
- 计算 str 长度
- 如果长度不超过 2 字节,则往 BlockDataOutputStream 写入 TC_STRING = (byte)0x74,否则写入 TC_LONGSTRING = (byte)0x7C
- 然后根据长度选择方法来往 BlockDataOutputStream 写入 str 和 length
我们来看 2 怎样计算长度:
/**
* 返回 UTF 编码的 String 的长度
*/
long getUTFLength(String s) {
int len = s.length(); // 拿到 s 的 Unicode 编码单元的个数
long utflen = 0;
for (int off = 0; off < len; ) {
int csize = Math.min(len - off, CHAR_BUF_SIZE); // 从 off 开始,读取最多 2 字节
s.getChars(off, off + csize, cbuf, 0); // 将 s 的数组拷贝到 cbuf 中
for (int cpos = 0; cpos < csize; cpos++) {
char c = cbuf[cpos];
if (c >= 0x0001 && c <= 0x007F) {
utflen++;
} else if (c > 0x07FF) {
utflen += 3;
} else {
utflen += 2;
}
}
off += csize;
}
return utflen;
}
可以看出它和 getLength 不一样,它会根据字符的区间来决定长度为 1/2/3。
再来看 4 拿到 str 和 length 后如何操作的:
void writeUTF(String s, long utflen) throws IOException {
if (utflen > 0xFFFFL) { // 长度超过 short 则 crash
throw new UTFDataFormatException();
}
// 将长度写到 buf 中(下面写 str 时会先写到 cbuf,然后再写到 buf),将 pos + 2
// 如果 pos 超过缓存大小,则将这个长度直接写到 DataOutputStream 中
writeShort((int) utflen); // 完成第 4 步,写长度
if (utflen == (long) s.length()) {
// 如果上面计算出来的 UTF 编吗长度和 UNICODE 编码长度相同
writeBytes(s);
} else { // 不同
writeUTFBody(s);
}
}
void writeLongUTF(String s, long utflen) throws IOException {
writeLong(utflen); // 同上,pos + 8
if (utflen == (long) s.length()) {
writeBytes(s);
} else {
writeUTFBody(s);
}
}
可以看出它先写入长度,再写入 s,写入 s 会根据编码格式来写入:
// 缓存整个 block 的数据
private final byte[] buf = new byte[MAX_BLOCK_SIZE];
// 缓存 str,长度为 256
private final char[] cbuf = new char[CHAR_BUF_SIZE];
// unicode 编码
public void writeBytes(String s) throws IOException {
int endoff = s.length();
int cpos = 0; // 从 cbuf 中开始读的位置
int csize = 0; // 要写到 cbuf 中的剩余字符长度
for (int off = 0; off < endoff; ) {
if (cpos >= csize) { // 将数据从 s 中写到 cbuf 缓存
cpos = 0;
csize = Math.min(endoff - off, CHAR_BUF_SIZE);
// 从 off 开始读取最多 2 字节到 cbuf。不直接
s.getChars(off, off + csize, cbuf, 0);
}
if (pos >= MAX_BLOCK_SIZE) { // 超过缓存长度 1K 就将当前流的数据写到底层流
drain();
}
int n = Math.min(csize - cpos, MAX_BLOCK_SIZE - pos);
int stop = pos + n;
while (pos < stop) { // 将 cbuf 中的数据写到 buf 中
buf[pos++] = (byte) cbuf[cpos++];
}
off += n;
}
}
可以看出写 string 的操作为:
- 将 str 读到 cbuf 缓冲区,大小为 256
- 如果 buf 缓冲区满了,则将 buf 写到流中
- 将 cbuf 存储的字符写到 buf 中。
- 没写完的话,继续从 1 循环
总结
写 String 的操作就是:
- 构造函数中会写入魔数和版本号
- 计算 str 的 UTF 编码格式的长度(str.len() 是 unicode 编码的长度)
- 写入类型,长度超过 2 字节则写入 long string 类型,即 0x7c。否则 0x74
- 将长度写入缓冲区,调用 writeShort/writeLong
- 将字符串拷贝的 cbuf 数组中,然后写到 cbuf 缓冲区中
整个 String 的写入就完成了,整个写入都是使用的 BlockDataOutputStream 操作的。再会过去看 String 的序列化图,是不是就很清晰了。
写对象流程
上面通过对 String 的讲解,已经可以理解 ObjectOutputStream 的大致流程,我们可以直接来看写入的对象的结构图:
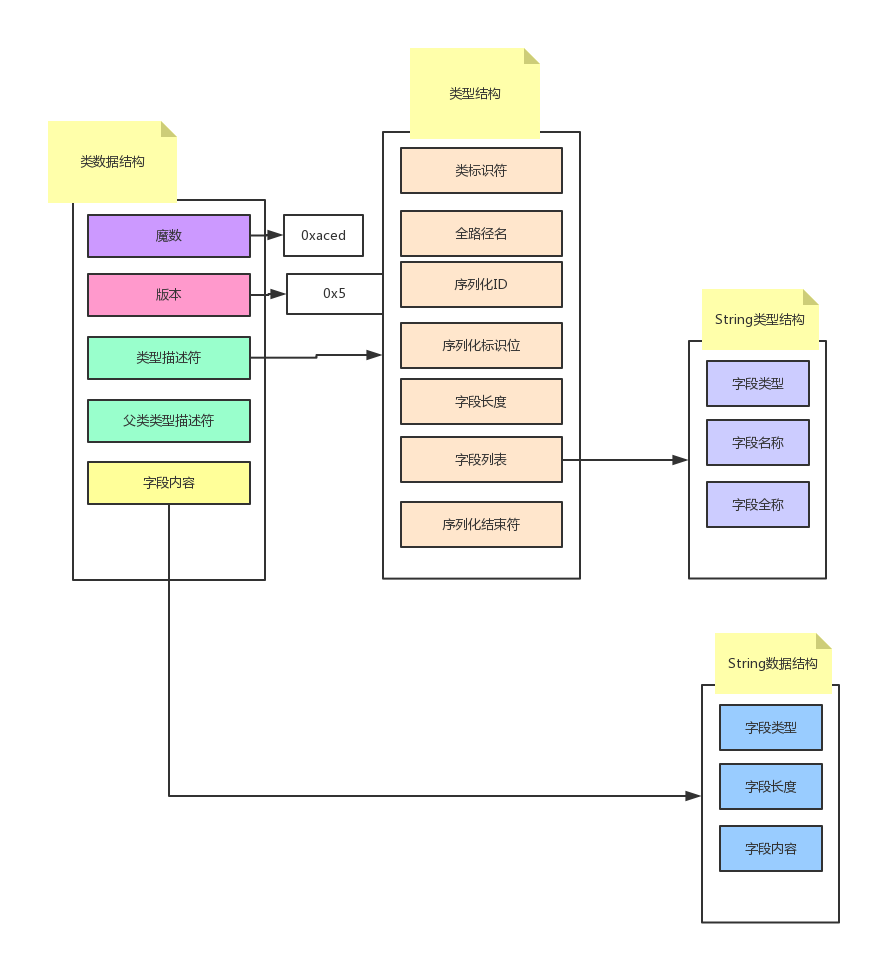 它的类型描述符会复杂一些,而且多了父类型描述符,字段内容和 string 差不多(类型,长度,内容)。
它的类型描述符会复杂一些,而且多了父类型描述符,字段内容和 string 差不多(类型,长度,内容)。
sample
public class SerialModel implements Serializable {
private String name;
// 省略 getter setter
}
public void f() {
try {
ByteArrayOutputStream byteArrayInputStream =
new ByteArrayOutputStream();
ObjectOutputStream objectOutputStream =
new ObjectOutputStream(byteArrayInputStream);
// 创建对象
SerialModel serialModel = new SerialModel();
serialModel.setName("Havana");
// 写到 ObjectOutputStream
objectOutputStream.writeObject(serialModel);
// 获取字节数组
byte[] objData = byteArrayInputStream.toByteArray();
// 将字节数组写到文件
FileOutputStream fileOutputStream =
new FileOutputStream(new File(Environment.getExternalStorageDirectory(), "objectSerial.txt"));
fileOutputStream.write(objData, 0, objData.length);
fileOutputStream.close();
} catch (IOException e) {
e.printStackTrace();
}
}
类结构中序列化数据与结构的对应内容
魔数: 0xaced
版本: 0x5
类型:Object:0x73
类型描述符
类标识符号: 0x72
全路径名: com.aya.SerialModel (String) 长度:`00 13`,内容:`63 6F 6D 2E 61 79 61 2E 53 65 72 69 61 6C 4D 6F 64 65 6C`
序列化id(serialVersionUID) 自动生成的serialVersionUID `09 9D B0 59 D6 38 AD 0C`
序列化标识位(byte): 2:SC_SERIALIZABLE (4:SC_EXTERNALIZABLE 2:SC_SERIALIZABLE 1:SC_WRITE_METHOD 16:SC_ENUM)
字段
字段长度 (short)`00 01`
遍历字段
字段类型 (byte) L: 字符串 `4C`
字段名称 (String) 字段长度:`00 04` 字段内容:`6E 61 6D 65`
字段类型全称 (String) Ljava/lang/String; `74` 字符串标识,`00 12` 字符串长度,字符串内容`4C 6A 61 76 61 2F 6C 61 6E 67 2F 53 74 72 69 6E 67 3B`
序列化结束符 `78`
父类描述符 NULL:`70` ,(内容与类型描述符一致,本例的父类是Object,所以内心描述符写入NULL)
字段内容: `74` 字符串标识,`00 05` 字符串长度,字符串内容`4B 61 72 65 6E`
写入序列化数据
基本类型直接写入,其他类型地柜调用序列化写入
类型: TC_REFERENCE 0x71
写入处理器: 0x7e0000+3
serialVersionUID
不指定该 id 的话,它会根据类名等来生成 SHA-1,然后计算出 hash,详情可以看下面:
- The class name.
- The class modifiers written as a 32-bit integer.
- The name of each interface sorted by name.
- For each field of the class sorted by field name (except private static and private transient fields:
- The name of the field.
- The modifiers of the field written as a 32-bit integer.
- The descriptor of the field.
- If a class initializer exists, write out the following:
- The name of the method,
. - The modifier of the method, java.lang.reflect.Modifier.STATIC, written as a 32-bit integer.
- The descriptor of the method, ()V.
- The name of the method,
- For each non-private constructor sorted by method name and signature:
- The name of the method,
. - The modifiers of the method written as a 32-bit integer.
- The descriptor of the method.
- The name of the method,
- For each non-private method sorted by method name and signature:
- The name of the method.
- The modifiers of the method written as a 32-bit integer.
- The descriptor of the method.
- The SHA-1 algorithm is executed on the stream of bytes produced by DataOutputStream and produces five 32-bit values sha[0..4].
- The hash value is assembled from the first and second 32-bit values of the SHA-1 message digest. If the result of the message digest, the five 32-bit words H0 H1 H2 H3 H4, is in an array of five int values named sha, the hash value would be computed as follows: long hash = ((sha[0] »> 24) & 0xFF) | ((sha[0] »> 16) & 0xFF) « 8 | ((sha[0] »> 8) & 0xFF) « 16 | ((sha[0] »> 0) & 0xFF) « 24 | ((sha[1] »> 24) & 0xFF) « 32 | ((sha[1] »> 16) & 0xFF) « 40 | ((sha[1] »> 8) & 0xFF) « 48 | ((sha[1] »> 0) & 0xFF) « 56;