最下面的引用里面的文章讲的很好很全,将全套的 Java IO 流的源码都讲了一遍,我这里仅仅梳理下个人觉得比较重要的知识。
分类
- 字节流:以字节为单位,每次次读入或读出是8位数据。可以读任何类型数据。
- 字符流:以字符为单位,每次次读入或读出是16位数据。其只能读取字符类型数据。
无论是字节流还是字符流,都分为输入流和输出流:
- 输入流:从文件读入到内存
- 输出流:从内存读出到文件
无论是输入流还是输出流,它们可以按照职责再划分为节点流和处理流:
- 节点流:直接与数据源相连,读入或读出。
- 处理流:相当于包装节点流,从而提升性能之类的。
结构图
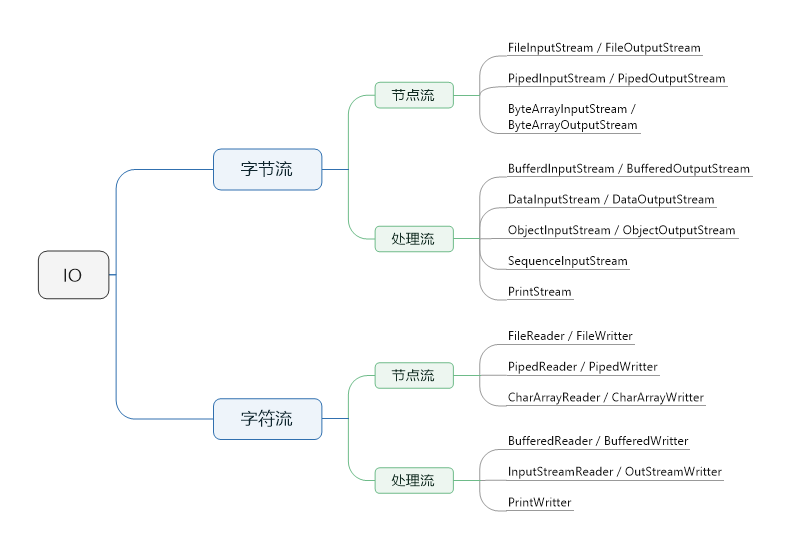
几个常用的流的职责
字节流的结点流
- FileInputStream / FileOutputStream:文件输入(/输出)流,直接从文件中读取特定长度的字节。
- PipedInputStream / PipedOutputStream:管道输入(/输出)流,用于线程间通信。输入流和输出流应在不同的线程,输出流的数据是写到输入流中。PipedOutputStream 接收一个 int 或者 byte 数组,并将它写到 PipedInputStream 的缓冲数组中。PipedInputStream 会从缓冲数组中读取字节。如果读的时候没有数据则会等待,并唤醒等待池中的线程来写数据。同样,写的时候写满了也会等,然后唤醒等待池中的线程来读数据。
- ByteArrayInputStream / ByteArrayOutputStream:ByteArrayInputStream 构造函数接收一个 byte 数组,然后从这个数组中读取数据。ByteArrayOutputStream 内部有一个 byte 数组,默认为 32。写数据都是往这个数组中写,数组满了则扩容(一般是按照原数组长度的2倍来扩充),内部有一个 writeTo(OutputStream) 方法来将 byte 数组中的数据写到其它流中。可以看出它们都是将数据写入到一个数组中,然后从这个数组中读到内存或者写到某个输出流中,根本不需要 close。
字节流的处理流
- BufferdInputStream / BufferedOutputStream:包装其余的输入(/输出)流,它们内部有一个默认大小为 8M 的缓冲数组,BufferdInputStream 在读取数据的时候,发现该缓冲数组为空,则从包装的输入流中读取缓冲数组剩余大小的数据到该数组中,然后再从该数组中读取所需要的个数的字节。BufferedOutputStream 会将写进来的字节(数组)写入到缓冲区,每次写满了就直接调用 flushBuffer() 方法将缓冲区的数据写到包装的输出流中,再继续从头开始写。
- DataInputStream / DataOutputStream:DataInputStream 构造函数接收一个输入流,然后调用 readInt(), readBoolean() 之类的方法来获取基本类型的数据。DataOutputStream 写数据时会将基本类型的数据拆分为 byte 写到输出流中。虽然它也是一个处理流,但可以看到它内部没有缓冲数组,所以它所包装的流可以考虑用 Buffered** 包装一下。可以看到它没有缓冲区,每次写都是直接将数据拆分后直接写入包装的输出流,所以它所包装的输出流最好是缓冲流之类的,所有数据写完后一起 flush 到真正的输出流。
- ObjectInputStream / ObjectOutputStream:它是流里面最复杂的。ObjectOutputStream 内部会创建一个 BlockDataOutputStream,数据的写操作都是由它来完成。它内部还组合了 DataOutputStream,在写基本类型的时候,如果缓冲区是满的,则直接 DataOutputStream 调用相应的方法写到输出流中。如果缓冲区没有满则直接写到缓冲区。数据的写入方式不同,它会写入魔数,版本号,类型,长度,内容之类的信息。
问题
为什么要提供 BufferedInputStream 之类的缓冲流?
原始的 IO 流每读一个字节就要写一个字节,每一次读写都是一次 IO 操作,效率很低。而缓冲流是一次性读取多个字节放到缓冲区中,然后一次性写入到磁盘,这样就能减少磁盘的操作,速度会快很多。这样的代价是要将数据写出的话,需要调用 flush 或 close 方法。
BufferedInputStream 等是继承自 FilterInputStream,它是一个装饰者模式,为其余的流提供一些 mark() reset() 之类的操作。
PipeInputStream 和 PipeOutputStream
这个流比较特别,它用于不同线程之间的相互通信,读和写互斥。它的输入输出是用一个循环缓冲数组来实现,它主要是将读和写的操作全部都放在 PipeInputStream 中,这样只需要给读写都加上对象锁,就达到了读写互斥的目的了。PipeOutputStream 通过 connect() 方法将 PipeInputStream 关联进来,然后在写的时候会调用 PipeInputStream 的写操作。注意不要在同一个线程中使用这2个流,会造成死锁。
DataInputStream 和 DataOutputStream
DataInputStream 是从底层流中读取基本数据类型,DataOutputStream 是将基本 Java数据类型写入输出流中。
- readShort:读取一个 short。我们知道 short 是2个字节,这个方法内部就会读取2个字节,然后将第一个字节往左挪8位,然后与第二个字节相加,就得到一个16位的short。
- readUnsignedShort:该方法是读取一个无符号的 short。这里重点讲下这个。我们知道 java 没有无符号数值,所有的数值类型的最高为都是符号位。那么如何将无符号转换成有符号呢?因为只要最高位为1,java就会把它当作负数,认为存的是补码。那么我们要做的就是使它的高为为0,并且又不改变原来的数据,那么解决办法就是扩充宽度,高位补0。譬如将 short 扩充为 int。但是并不是直接强制转换就可以了。我们知道当扩充宽度的时候,如果高位为0,则会补0;但如果高位为1,则会往前面补1,这样才不会改变原始的值。而我们要做的是高位为1时,扩充宽度时,依然要补0。做法就是将原来的数据与上一个低位全为1,高位全为0的字面常量。如 byte 就可以与上 0x0FF,字面常量默认为 int 类型。如 1000 0000 0000 0001 & 0000 0000 0000 0000 1111 1111 1111 1111,此时先将 short 转换成 int,此时高位会补1,那么就变成 1111 1111 1111 1111 1000 0000 0000 0001 & 0000 0000 0000 0000 1111 1111 1111 1111,最终的结果就是 0000 0000 0000 0000 1000 0000 0000 0001。即原来的二进制没变,高为全部补0,这样 java 就以为它为正数了。 获取无符号 int 类型如此类推,只不过将 0x0FF 变成 0X0FFFFFFFF。 要注意的是,char 类型扩充宽度的时候,只会往高位补0。 从上面就可以看出为什么这个方法返回的是 int 而不是 short。
- readUnsignedByte:经过上面的理解,你可能以为这个方法会返回一个 short,高位为0,其实它和 readByte 没有区别。因为 byte 本身就不是数,也就不用区分正负。