Java String类为什么是final的?
- 为了实现字符串常量池
- 为了线程安全
- 为了 String 的 HashCode 的不可变性
首先我们要了解 final 的用途。他可以修饰类、方法和变量。修饰类表示该类不可继承,修饰方法表示方法不能被重写,修饰变量(无论是类属性、对象属性、形参还是局部变量)则变量必须进行初始化操作,并且该变量不可变。
用 final 来修饰 String 主要是从安全性和效率考虑的。我们来看下 JDK 的源码:
public final class String implements Serializable, Comparable<String>, CharSequence {
private final char[] value;
private int hash;
将 String 用 final 修饰来表示它不可被继承,用 final 修饰 char[] value 来表示被存储的数据不可更改(它仅仅表示引用地址不可变,并不代表该数组的值不可变)。
final int[] array = {1, 2, 3};
array[2] = 5; // final 数组的值是可变的
可以看出这个 final 并不完全是 String 不可变的原因,起作用的还有 private。
那么为什么要将 String 设置为不可变呢?
- 只有当字符串不可变时才有可能实现字符串常量池。字符串常量池的实现可以在运行时节约很多 heap 空间,因为不同的字符串常量都是指向池中的同一个字符串。如果它是可变的,string intern pool 就不能实现,因为如果变量的值被改变了,那么其他所有只想该值的变量都会发生改变。
- 如果 String 可变会引起严重的安全问题。譬如数据库的用户名、密码都是以字符串的形式传入来获得数据库连接,如果它是可变的,那么hacker 就可以改变字符串指向的对象的值,造成安全漏洞。
- String 不可变让它是线程安全的。同一个字符串可以被多个线程共享。
- String 不可变,那么在它创建的时候就可以将 HashCode 缓存起来,不需要重新计算。这使得字符串很适合做 Map 中的键,字符串的处理速度要快过其它键的值。
String 常量池
字符串常量池的设计思想
字符串的分配,和其他的对象分配一样,耗费高昂的时间与空间代价,作为最基础的数据类型,大量频繁的创建字符串,极大程度地影响程序的性能。 JVM 为了提高性能和减小内存开销,在实例化字符串常量时进行了优化,即为它开辟了一个字符串常量池,类似缓存区。在创建字符串常量时,首先查询字符串常量池是否存在该字符串,存在的话返回引用实例,否则实例化该字符串并放入池中。
String 进入常量池的时机
- 编译期:通过双引号声明的常量(包括显示声明、静态编译优化后的常量,如”1” + “2”优化为”12”)在前端编译期将被静态地写入 class 文件中的“常量池”。该“常量池”会在类加载后被载入“内存中的常量池”,也就是我们平是说的常量池。同时,JIT优化也可能产生类似的常量。
- 运行期:通过调用 String.intern() 方法可能将 String 对象动态的写入常量池中。
intern() 方法:
/**
* Returns a canonical representation for the string object.
* <p>
* A pool of strings, initially empty, is maintained privately by the
* class {@code String}.
* <p>
* When the intern method is invoked, if the pool already contains a
* string equal to this {@code String} object as determined by
* the {@link #equals(Object)} method, then the string from the pool is
* returned. Otherwise, this {@code String} object is added to the
* pool and a reference to this {@code String} object is returned.
* <p>
* It follows that for any two strings {@code s} and {@code t},
* {@code s.intern() == t.intern()} is {@code true}
* if and only if {@code s.equals(t)} is {@code true}.
* <p>
* All literal strings and string-valued constant expressions are
* interned. String literals are defined in section 3.10.5 of the
* <cite>The Java™ Language Specification</cite>.
*
* @return a string that has the same contents as this string, but is
* guaranteed to be from a pool of unique strings.
*/
@FastNative
public native String intern();
可以看出如果常量池中存在该字符串则会返回池中的 String,否则这个 String 对象就会被添加到常量池中并且返回指向该 String 对象的引用。
我们来看下 JNI 最后调用了 C++ 实现的 StringTable::intern() 方法:
oop StringTable::intern(Handle string_or_null, jchar* name,
int len, TRAPS) {
unsigned int hashValue = java_lang_String::hash_string(name, len);
int index = the_table()->hash_to_index(hashValue);
oop string = the_table()->lookup(index, name, len, hashValue);
// Found
if (string != NULL) return string;
// Otherwise, add to symbol to table
return the_table()->basic_add(index, string_or_null, name, len,
hashValue, CHECK_NULL);
}
oop StringTable::lookup(int index, jchar* name,
int len, unsigned int hash) {
for (HashtableEntry<oop>* l = bucket(index); l != NULL; l = l->next()) {
if (l->hash() == hash) {
if (java_lang_String::equals(l->literal(), name, len)) {
return l->literal();
}
}
}
return NULL;
}
可以看出,它是在 the_table() 表中根据查找字符串,如果存在则返回,否则添加到表中。StringTable 是一个大小为1009(jdk7及以后,该长度可以通过一个参数指定)的 HashTable,它先得到这个字符串的 hashCode,然后通过 hashCode 查找到该字符串的 index,再去该 index 对应的桶中的链表(考虑到哈希碰撞)中查找该字符串。
jdk6和jdk7下String#intern()的区别
问题:String s = new String("abc");创建了几个对象?
它创建了2个对象:一个内容为”abc”,存储在常量池;一个内容为”abc”,存储在堆中。
再来看一段代码:
public static void main(String[] args) {
String s = new String("1");
s.intern();
String s2 = "1";
System.out.println(s == s2);
String s3 = new String("1") + new String("1");
s3.intern();
String s4 = "11";
System.out.println(s3 == s4);
}
结果:
# jdk6下
false false
# jdk7下
false true
再来看:
public static void main(String[] args) {
String s = new String("1");
String s2 = "1";
s.intern();
System.out.println(s == s2);
String s3 = new String("1") + new String("1");
String s4 = "11";
s3.intern();
System.out.println(s3 == s4);
}
结果:
# jdk6下
false false
# jdk7下
false false
对于 JDK6:
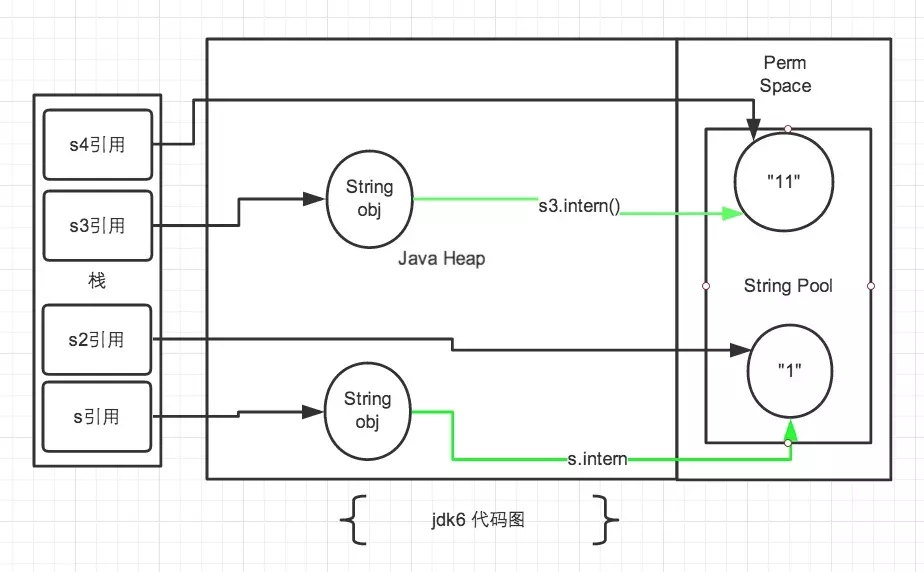
绿线表示 String 对象的内容指向;黑线表示地址指向
jdk6 中所有打印都为 false,因为 jdk6 的常量池放在 Perm 区中,和正常的 Heap(指 Eden、Surviver、Old 区)完全分开。也就是使用引号声明的字符串都是通过编译和类加载直接载入常量池,位于 Perm 区;new 出来的 String 位于 Heap (E、S、O) 中。Perm 区的对象地址和 Heap 中的对象地址比较肯定不同。
Perm 区主要存储一些加载类的信息、静态变量、方法片段、常量池等。
对于 JDK7:
由于 Perm 区默认大小只有4M,容易出现OOM。所以 JDK7 将字符串常量池从 Perm 区移到正常的 Heap(E、S、O) 中了。
Perm 区为永久代。本身使用永久代来实现方法区就容易遇到 OOM,而且方法区存放的内容大小很难估计,没必要放在堆中管理。JDK8 已经取消永久代,在堆外新建了 Metaspace 实现方法区。
- 针对上面第一段代码:
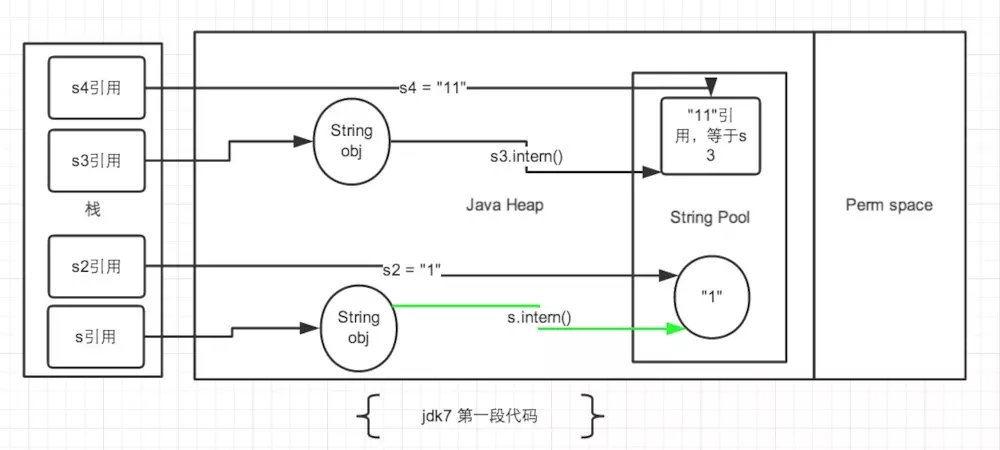 首先看 s3 和 s4:
首先看 s3 和 s4:
String s3 = new String("1") + new String("1")生成了多个对象,s3 最终指向堆中的”11”,此时常量池中没有”11”s3.intern()将 s3 中的字符串”11”放入常量池,因为此时常量池中不存在字符串”11”,所以它和 jdk6 一样,在常量池中生成一个 String 对象”11”,由于 jdk7 的常量池在 Heap 中了,那么它就不需要再存储一份对象了,而是直接存储堆中的引用,也就是 s3 的引用地址s4 = "11"会直接去常量池查找,如果没有找到就会创建。这时常量池已经存在,则会直接返回 s3 的引用地址,也就是堆中的地址- 那么 s3 和 s4 都是指向堆中的地址,所以 s3 == s4 为 true
再来看 s 和 s2: String s = new String("1")会生成2个对象,常量池中的”1”和堆中的”1”,此时 s 指向堆中的”1”s.intern()由于上一句已经在常量池中创建了”1”,所以此处什么都不做String s2 = "1",此时 s2 就指向常量池中”1”- 由于 s 指向堆中的”1”,s2 指向常量池中的”1”,所以 s == s2 为 false
- 针对上面第二段代码:
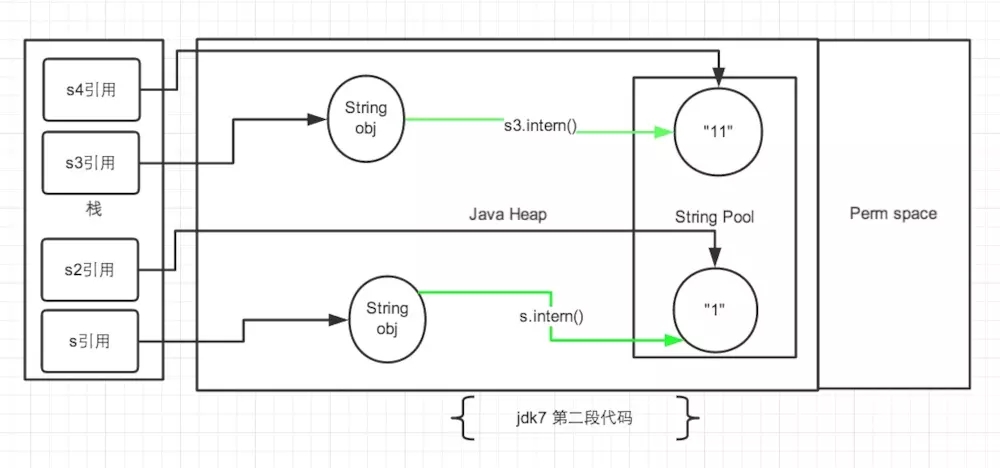
首先看 s3 和 s4:String s3 = new String("1") + new String("1"),s3 最终指向堆中的”11”,此时常量池中没有”11”String s4 = "11",将”11”放入常量池,然后 s4 指向常量池中的”11”s3.intern(),由于上一句已经在常量池中创建了”11”,所以此时什么都不做- 最终 s3 指向堆中的”11”,而 s4 指向常量池中的 “11”。 所以 s3 == s4 为 false
再看 s 和 s2: String s = new String("1")会先在常量池中创建一个”1”的对象,然后 new String() 会在堆中分配内存并把字符串常量池中的”1”复制给堆中的这个 String,即创建2个对象,常量池中的”1”和堆中的”1”,此时 s 指向堆中的”1”String s2 = "1",s2 指向常量池中的”1”s.intern()由于常量池中已经有”1”,所以此时什么都不做- 同样,s == s2 也为 false
区别小结
- jdk7 将 String 常量池从 Perm 区移到 Heap 区
- 调用 String#intern() 方法时,堆中有该字符串常量时而常量池中没有,则直接在常量池中保存堆中对象的引用,而不会在常量池中重新创建对象。
实现基础
从常量池的实现就可以看出实现该优化的基础是因为字符串不可变,因为内部是采用 HashTable 所以不用担心数据冲突进行共享。运行时,由于字符串常量池中的这个表,总是为池中的每一个唯一的字符串对象维护一个引用,这意味着它会一直引用字符串常量池中的对象,所以常量池中的对象不会被垃圾回收器回收。
String、StringBuilder、StringBuffer
- StringBuffer 和 String 是线程安全的,StringBuilder 非线程安全
- StringBuilder 和 StringBuffer 对象存储在堆中,String 对象存储在字符串常量池中
- String 不可变,其余2个可变
StringBuilder 和 StringBuffer 代码层面上的区别
public final class StringBuffer extends AbstractStringBuilder implements Serializable, CharSequence {
private transient char[] toStringCache;
static final long serialVersionUID = 3388685877147921107L;
private static final ObjectStreamField[] serialPersistentFields;
public StringBuffer() {
super(16);
}
public StringBuffer(int var1) {
super(var1);
}
public StringBuffer(String var1) {
super(var1.length() + 16);
this.append(var1);
}
public StringBuffer(CharSequence var1) {
this(var1.length() + 16);
this.append(var1);
}
public synchronized int length() {
return this.count;
}
public synchronized int capacity() {
return this.value.length;
}
public synchronized void ensureCapacity(int var1) {
super.ensureCapacity(var1);
}
public synchronized void trimToSize() {
super.trimToSize();
}
}
public final class StringBuilder extends AbstractStringBuilder implements Serializable, CharSequence {
static final long serialVersionUID = 4383685877147921099L;
public StringBuilder() {
super(16);
}
public StringBuilder(int var1) {
super(var1);
}
public StringBuilder(String var1) {
super(var1.length() + 16);
this.append(var1);
}
public StringBuilder(CharSequence var1) {
this(var1.length() + 16);
this.append(var1);
}
public StringBuilder append(Object var1) {
return this.append(String.valueOf(var1));
}
public StringBuilder append(String var1) {
super.append(var1);
return this;
}
public StringBuilder append(StringBuffer var1) {
super.append(var1);
return this;
}
可以看出 StringBuffer 和 StringBuilder 的区别就是在方法上加了 synchronized。本质上,他们都是改变 char 数组中的内容,他们对外公开了修改 char 数组的方法,而 String 未公开。
性能问题
速度比较:StringBuilder > StringBuffer > String。 StringBuilder > String 主要原因是在 String 中,每次拼接新的字符串,都会 new 一个 StringBuilder 对象,也就是说如果拼接N次,就需要 new 出来 N 个 StringBuilder 对象,这样无疑上速度会慢很多。StringBuilder > StringBuffer 是因为 StringBuffer 加了 synchronized 修饰,其余的操作都是继承自 AbstractStringBuilder 父类。
JDK6 中 subString 引发的内存泄漏
jdk6 中的 subString 的实现:
public String substring(int beginIndex, int endIndex) {
...
return ((beginIndex == 0) && (endIndex == count)) ? this :
new String(offset + beginIndex, endIndex - beginIndex, value);
}
它创建了一个新的 String,并将原 String 的 value 数组传到构造函数中,我们来看下构造函数:
// Package private constructor which shares value array for speed.
String(int offset, int count, char value[]) {
this.value = value; //新的 String 强引用住旧 String 的 value 数组
this.offset = offset;
this.count = count;
}
可以看出,它出于效率考虑,新字符串与旧字符串公用一个 value 数组,导致旧字符串不能被释放。新的 JDK 已经修改了构造函数:
public String(char value[], int offset, int count) {
...
this.offset = 0;
this.count = count;
this.value = Arrays.copyOfRange(value, offset, offset+count);
}
这样旧不会引用原 String 的 value 数组,从而解决内存泄漏问题。